
IaaS, PaaS, SaaS: Choosing the Wrong One Is an Engineering Decision You'll Regret

Cloud infrastructure engineer. Writes about the decisions that look fine on day one and hurt on day 300.
TL;DR: IaaS gives you raw infrastructure and full control, you manage the OS, runtime, and everything above it. PaaS abstracts that away so you can focus on code, at the cost of flexibility and, at scale, margin. SaaS means you use finished software instead of building it. The wrong pick rarely fails immediately, it fails 18 months later when you're scaling fast, the bill has tripled, and migrating out requires rebuilding things you thought were solved. This article walks through three real patterns of how that happens and what the warning signs looked like in advance.
The decision rarely feels like a decision. You pick Heroku because the team used it at the last company and it deploys in one command. You provision EC2 instances because the senior engineer knows AWS and IaaS gives you control. You license Salesforce because procurement wants it off the engineering team's plate. Six months later, you are building features. Twelve months later, the infrastructure is working. Eighteen months later, the bill arrives, or the ceiling does, and suddenly the thing you chose in a 30-minute conversation is the thing requiring a three-month migration.
The models themselves are not the problem. IaaS, PaaS, and SaaS each fit a real set of circumstances. The problem is that teams pick based on familiarity, convenience, or what they can demo by Friday, and then discover the trade-offs at exactly the wrong moment: when they are moving fast, when customers are waiting, and when switching costs are highest.
These are three patterns of how that plays out.
The Team That Chose PaaS and Hit the Ceiling at Scale
A four-person engineering team building a B2B analytics product launched on Heroku in early 2023. It was the right call. Heroku's deployment model meant they could ship without an ops engineer, the managed Postgres add-on removed database administration entirely, and the dyno pricing at their traffic levels was cheaper than the engineering time that IaaS would have required. They went from idea to production in six weeks.
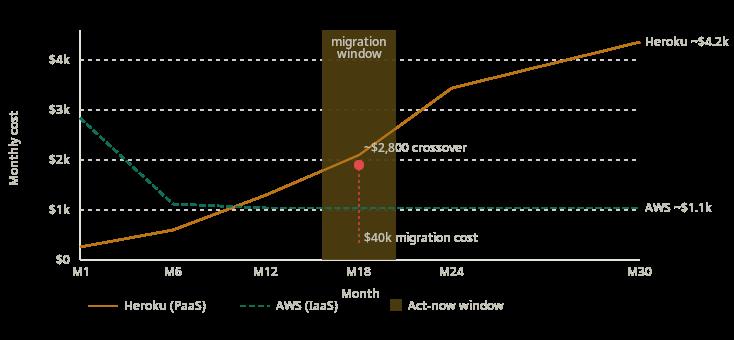
By mid-2024, they had 200 business customers and were processing roughly 40GB of data per day. Their Heroku bill was $4,200 a month, two Performance-M dynos, the Heroku Postgres Standard-3 plan, and a handful of add-ons for logging and caching. The architecture was clean and the team was productive. Then they ran a projection.
At their current growth rate, the same workload on AWS, three EC2 m6i.xlarge instances behind an Application Load Balancer, RDS Postgres on a db.r6g.large, and ElastiCache for the caching layer, would cost approximately $1,100 a month. The $3,100 monthly gap was $37,200 a year. At a 5x revenue multiple, that gap was worth $186,000 in enterprise value if they ever raised or sold.
The migration took eleven weeks and one dedicated engineer. Containerising the application, configuring auto-scaling groups, setting up RDS parameter groups to match their Postgres configuration, and rebuilding the deployment pipeline in GitHub Actions, none of it was technically hard, but all of it took time that engineer was not spending on product. The total cost of the migration, including opportunity cost at that engineer's fully-loaded rate, was around $40,000.
They broke even in about 13 months.
The lesson is not that Heroku was wrong. Heroku was exactly right for the first 18 months. The lesson is that they had no plan for what happened after that. The signal they missed: when the Heroku bill crossed $2,000 a month, that was the moment to model the IaaS alternative. They let it run to $4,200 before anyone looked at the numbers.
The rule of thumb that holds up: when a PaaS bill hits roughly $5,000 per month, it is time to model the IaaS equivalent. The inflection point where IaaS becomes cheaper than PaaS, accounting for operational overhead, typically lands somewhere between $2M and $5M ARR. Missing that window by six months costs more than the migration itself.
Warning signals this team missed:
- Heroku bill crossed $2,000/month with no IaaS cost model on file
- No defined trigger to revisit the infrastructure decision after launch
- Migration was reactive, forced by the bill, not planned during a quiet period
- The 11-week migration window fell during a period of active customer growth
The Team That Chose IaaS Too Early and Burned Engineering Time on Infrastructure
A two-person startup building a developer tool chose AWS from day one because the founder had spent five years at a company running on EC2 and knew the platform well. They provisioned a VPC, set up EC2 instances, configured RDS, wired up an Application Load Balancer, and wrote Terraform for all of it. It took three weeks.
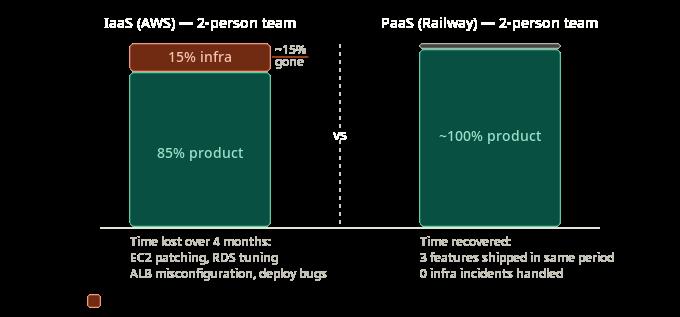
Then they spent the next four months shipping product, interrupted every two to three weeks by infrastructure work. An EC2 instance needed patching. The RDS instance hit a connection limit they had not configured correctly. A deploy went wrong because their deployment script had an edge case on instance restart. The ALB health check was misconfigured and started routing traffic to an unhealthy instance.
None of these problems were catastrophic. Each one took four to eight hours to diagnose and fix. But across four months, the infrastructure maintenance consumed roughly 15% of their combined engineering time, time that two engineers at an early-stage company cannot afford to lose.
A competitor building a similar tool on Railway launched three features in the same period. Railway's build and deploy pipeline handled what the founder had spent three weeks implementing in Terraform. Their managed Postgres required zero tuning. Their deployment was a git push.
The two-person team eventually migrated to Railway for the core application and kept AWS only for a data processing pipeline that genuinely needed the control IaaS provided. The migration took four days.
The mistake was applying a solution suited to a 20-person engineering team with dedicated ops capacity to a two-person team that needed to ship. IaaS is genuinely better for many things, custom networking requirements, specific compliance configurations, workloads where per-unit compute cost matters at volume. None of those applied at their stage. They chose IaaS because the founder knew it, not because the team needed it.
The signal they missed: if you do not have an engineer whose primary focus can include infrastructure operations, IaaS is probably not the right model yet. The question is not "do we know how to run IaaS?" it is "can we afford the time cost of running it at this stage?"
Warning signals this team missed:
- Team size (2 engineers) had no room to absorb infrastructure incidents without product impact
- IaaS was chosen based on founder familiarity, not team capacity
- No explicit decision about who owned infrastructure operations day to day
- A competitor on PaaS shipped faster in the same window without any ops overhead
The Team That Built What They Should Have Bought
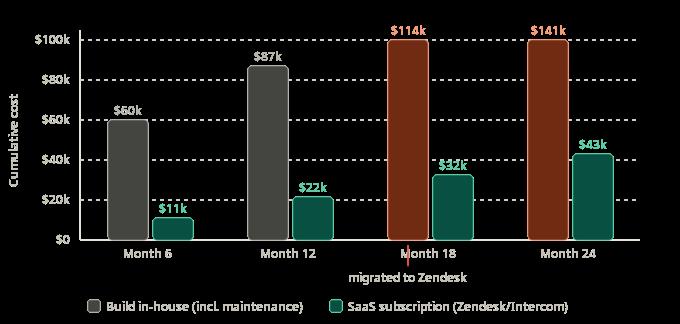
A mid-size SaaS company with 18 engineers decided in late 2022 to build their own internal customer support tooling rather than license Intercom or Zendesk. The reasoning was coherent at the time: the off-the-shelf tools did not integrate cleanly with their existing data model, the licensing cost for their support team of 12 agents would have been $1,800 a month, and two engineers estimated they could build a functional internal version in six weeks.
It took four months. The initial build worked, and then the requests started. The support team needed a tagging system. Then SLA tracking. Then a reporting dashboard. Then email threading to behave differently for a specific customer tier. Then mobile notifications. Each feature was reasonable. None of them were the product the company was supposed to be building.
By mid-2024, one engineer was spending roughly 30% of their time maintaining and extending the internal support tool. At a fully-loaded cost of $180,000 per year, that was $54,000 annually in engineering capacity spent on software that was available off the shelf for $21,600 per year.
The real cost was not just the dollars, it was the compounding effect of a distracted engineering team. Features that should have shipped in Q3 2023 slipped to Q1 2024. A product manager left partly because roadmap items kept getting deprioritised. Two customer escalations during a six-week period where the internal tool had a bug in its SLA tracking were handled manually, which cost the head of support 20 hours of time.
They migrated to Zendesk in March 2024. The migration took two weeks. The internal tool was deprecated. The engineer who had been maintaining it spent the next quarter shipping a feature that directly contributed to a pricing tier expansion.
The mistake was calculating the build cost and ignoring the maintenance cost. A custom-built internal tool is not a one-time investment, it is a permanent operational commitment. The Intercom and Zendesk pricing that looked expensive in 2022 was a flat, predictable subscription. The build-it-yourself path became a variable, growing tax on engineering capacity.
The signal they missed: when a tool's primary value is operational, handling a workflow, routing communication, tracking tickets, and not a product differentiator, that is a SaaS problem, not an engineering problem. The question is not "can we build this?" Almost always, the answer is yes. The question is "should this be on our engineering roadmap at all?"
Warning signals this team missed:
- Build estimate covered initial development only, ongoing maintenance was never costed
- Feature requests from the support team began within weeks of launch, extending the scope indefinitely
- One engineer was at 30% maintenance capacity for over a year with no plan to wind that down
- The $1,800/month SaaS cost felt expensive; the $54,000/year in engineering capacity did not
The Decision Framework That Would Have Changed All Three Outcomes
These three situations share a structure. In each case, the team made a reasonable-sounding decision without asking the question that would have changed the outcome: what is the cost of this choice in 18 months, not today?
| Model | Use it when | Avoid it when | Re-evaluate trigger |
|---|---|---|---|
| PaaS | Team < 6 engineers, no dedicated ops, need to ship fast | Bill exceeds ~$5k/month, workload needs OS-level tuning | Monthly bill crosses $2k to $3k |
| IaaS | Custom networking, compliance requirements, compute economics at scale matter | Team < 4 to 5 engineers with no ops capacity, early stage | Infra incidents consuming > 10% of engineering time |
| SaaS | Tool is operational, not a product differentiator, 2-year build cost exceeds subscription | Tool is a core product feature, requires deep data model integration | Maintenance reaches 0.25+ FTE of engineering time |
The model that fits your situation today is probably not the model that fits in 24 months. The teams that manage this well are not the ones that pick correctly once, they are the ones that revisit the decision at defined trigger points rather than waiting for the pain to arrive.
Conclusion
None of these were catastrophic failures. The PaaS team migrated successfully and came out ahead. The IaaS startup shipped a good product. The company that built its own support tooling eventually fixed it. But in each case, the cost of the wrong choice, paid in engineering time, in dollars, in delayed features, was significantly higher than it needed to be.
The right question is not "which model is best?" It is "what does our team actually need to operate this, and what will that cost us when the workload is three times what it is today?" Ask that question before the first infrastructure decision. Write the answer down. Set a calendar reminder to revisit it in six months. The model is just a starting point, the discipline is knowing when to change it.
Since you're here: Ozigi also ships a handful of free, no-signup tools — a free cold email generator, a free LinkedIn outreach generator, a free long-form article generator, and a free newsletter generator. Worth a look if any of that's useful to you.
About the author
Cloud infrastructure engineer. Writes about the decisions that look fine on day one and hurt on day 300.


